참고 출처 : 실무자를 위한 파이썬 100제
## 웹 서버에 요청하고 응답하는 과정
Request : 사용자가 웹서버에게 웹 페이지 정보를 달라고 요청하는 과정이다.
Response : 웹 서버가 웹 페이지 정보를 보내는 과정을 응답이라고 함.
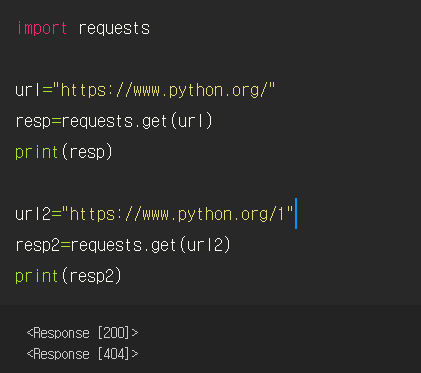
1. Request의 get()함수를 사용하여 웹 서버에 GET요청을 보낸다.
2. 파이썬 홈페이지의 URL을 저장한 변수를 함수의 매개변수로 전달한다.
3. 웹 서버가 응답한 내용을 resp 변수에 저장한다.
4. 응답 결과를 출력한다.
## 웹 페이지 소스코드 확인하기
1. request 모듈 불러오기
2. url 변수에 파이썬 홈페이지 url 저장
3. 웹 서버에 get 요청을 보내고, 응답한 내용을 변수 resp에 저장한다.
4. HTML 소스 코드를 확인하려면 test 속성을 지정한다.

## 로봇 배제 표준
- 웹 페이지에 접근하기 전에 반드시 로봇 배제 표준을 확인하고 가이드라인을 준수해야 한다.
- 크롤링으로 취득한 자료를 임의로 배포하거나 변경하는 등의 행위는 저작권 침해할 수 있으니까 규정 준수 필수
- robots.txt 파일은 루트 디렉터리에 위치한다. 로봇 배제 표준을 담고 있는 파일이다.
- www.python.org/robots.txt'로 확인하면 됌

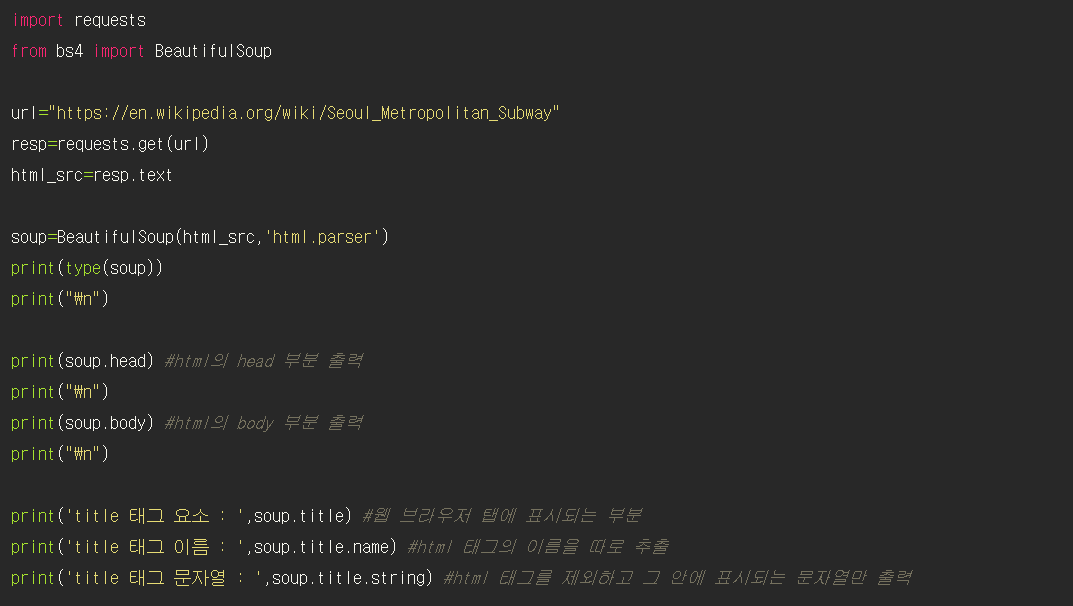
## BeautifulSoup 객체 만들기
- BeautifulSoup 라이브러리를 이용하여 정적 웹 페이지에서 정보를 추출한다.
- 파싱 : HTML 소스코드를 해석하는 과정
BeautifulSoup 함수는 매개변수로 전달받은 html 소스코드를 해석해서 BeautifulSoup 객체를 생성한다.
HTML을 파싱하는 적절한 구문 해석기를 함께 입력해야 한다.
print(type(soup)) => <class 'bs4.BeautifulSoup'>, 즉 bs4 라이브러리에서 불러온 BeautifulSoup 클래스라는 것을 확일할 수 있다.
## 크롬 개발자 도구
Ctrl+shift+I or F12
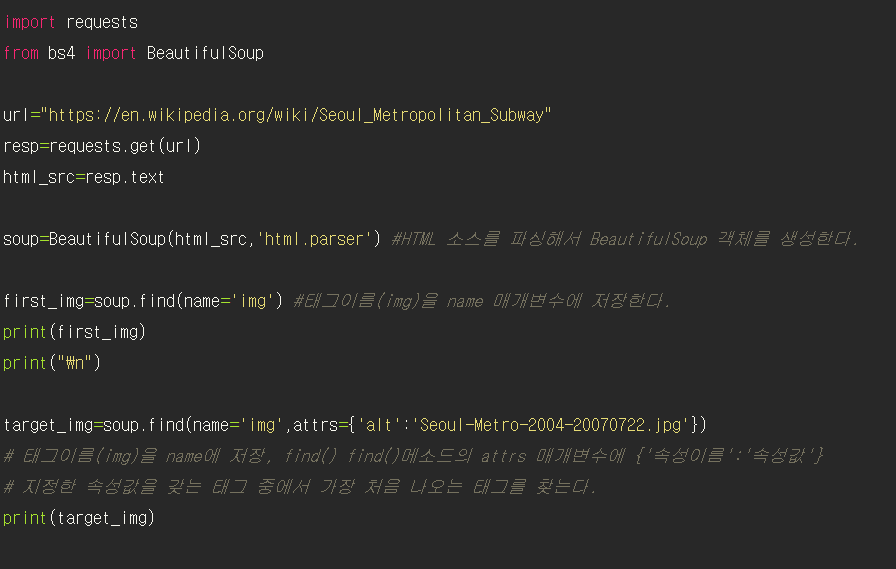
BeautifulSoup 클래스의 find() 메소드는 HTML 문서에서 가장 처음으로 만나는 태그를 한 개 찾는다.
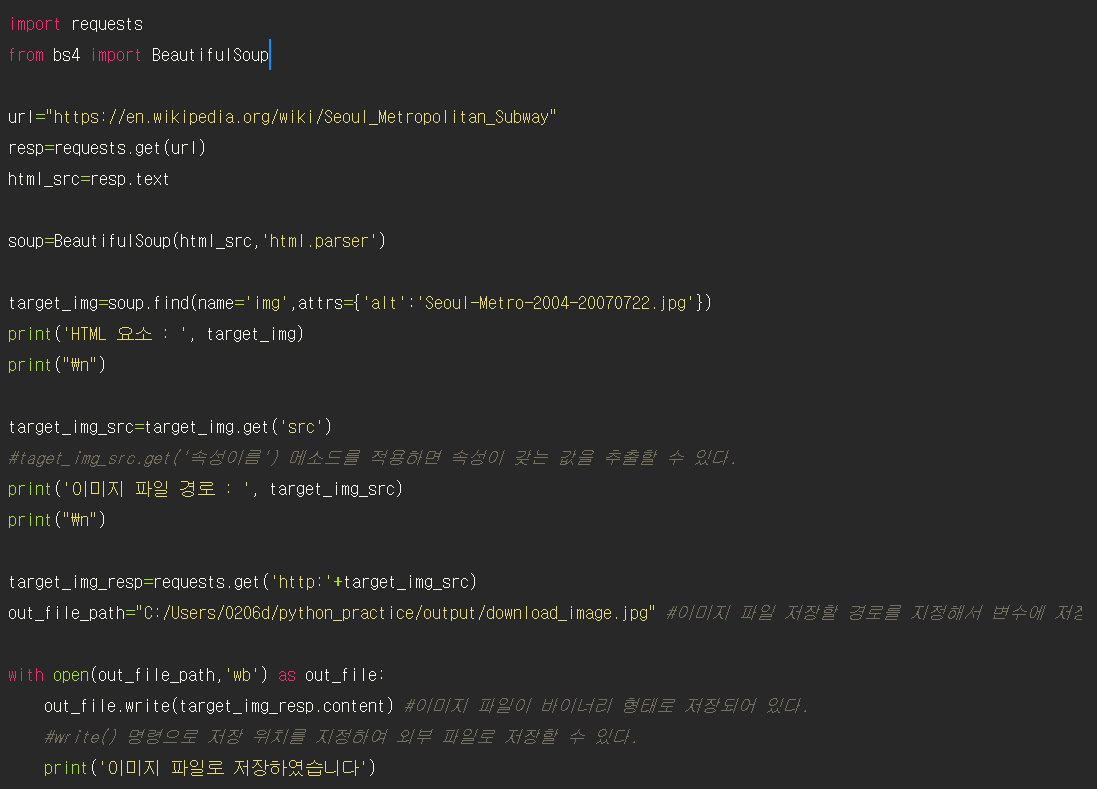
## 웹 문서의 그림 이미지 파일을 pc에 저장하기
img 태그 안에 src 속성을 들여다보면 소스파일 url을 볼 수 있는데, 이를 이용해서 직접 다운로드 시도
taget_img_src.get('속성이름') 메소드를 적용하면 속성이 갖는 값을 추출할 수 있다.
with open(파일 경로, 모드) as 파일객체 :
처리코드
>> 파일 스트림을 다루는 데 있어서 파이썬에서 제공하는 강력한 기능
>> 파일을 열고 해당 구문이 끝나면 자동으로 닫히게 해주는 기능
>> with as 구문을 빠져나가면 자동으로 close()함수가 호출됌
>> 네트워크 스트림을 다루는 소켓 프로그래밍과 같은 곳에서도 활용한다.
>> with 모드
1. wb : 바이너리 모드에서 쓰기 작업하는 동안 파일은 열려져있다 (w+b)
## 웹 문서에 포함된 모든 하이퍼링크 추출하기
- BeautifulSoup 클래스의 find_all() 메소드 사용
- find_all("태그이름") => 웹 문서에서 해당하는 모든 태그를 찾아서 리스트 형태로 리턴한다.
wiki_links=soup.find_all(name="a",href=re.complie("/wiki/"),limit=3)
>> a 태그의 href 속성이 포함하는 문자열을 따로 지정하면 해당 문자열이 포함된 a태그만을 찾는다.
>> 출력 길이를 제한하기 위해 limit 매개변수를 3으로 설정한다.
>> 즉 /wiki/문자열이 링크에 포함되어 있는 a 태그를 3개 찾아서 변수에 저장한다.

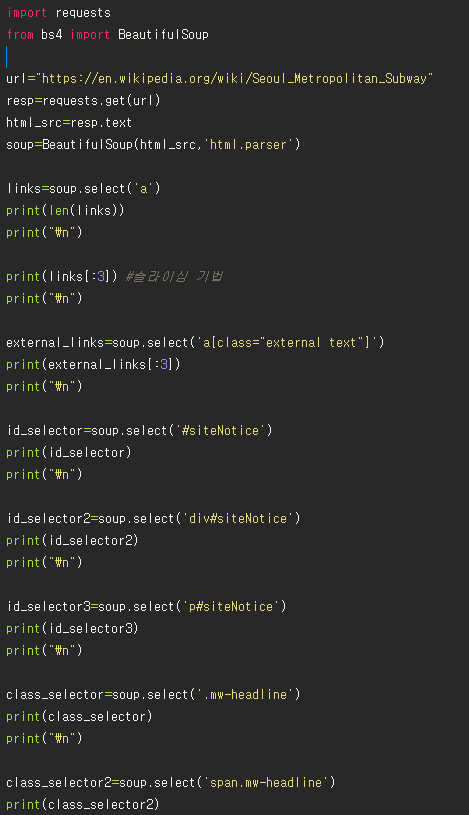
## css Selector 활용하기
- select()메소드가 리턴하는 객체는 파이썬 리스트이다.
- HTML요소 부분만을 따로 추출하려면 파이썬 리스트의 원소 인덱싱을 사용한다. Subway_image[0]
- CSS 선택자를 이용해서 같은 레벨에 있는 다른 태그까지 한꺼번에 선택할 수 있다.
-

## CSS Selector 활용하기2
- select()메서드는 find_all()과 비슷하다. 찾으려는 태그 이름을 매개변수로 넘겨주면 웹 문서에서 해당하는 모든 태그를 찾아서 리스트 형태로 반환해준다.
- css의 id 선택자를 활용, id 선택자는 고유한 값을 가지기 때문에 한 개의 리스트만 찾아낸다.
>> #id속성값
- 클래스 선택자를 사용하면 같은 클래스를 갖는 여러 태그들을 동시에 찾을 수 있다.
>> .class속성값 으로 표현한다.
soup.find(name='img',attrs={'alt':'Seou-~.jpg'})
with open(out_file_path,'wb') as out_file: out_file.write(target_img_resp.content)
#이미지 파일이 바이너리 형태로 저장되어 있다.
#write() 명령으로 저장 위치를 지정하여 외부 파일로 저장할 수 있다.
print('이미지 파일로 저장하였습니다')
wiki_links=soup.find_all(name="a",href=re.compile("/wiki/"),limit=3)
external_links=soup.find_all(name="a",attrs={"class":"external text"},limit=3)
subway_image=soup.select('#mw-content-text > div.mw-parser-output > table:nth-child(3) > tbody > tr:nth-child(1) > td > a > img')
subway_image2=soup.select('tr>td>a>img')
external_links=soup.select('a[class="external text"]')
id_selector2=soup.select('div#siteNotice')
'여니의 프로그래밍 study > 파이썬' 카테고리의 다른 글
| [파이썬] 웹 스크래핑 (검색어를 url 코드로 변환) (1) | 2021.01.11 |
|---|---|
| [주피터 노트북] pdf 파일로 저장하기 : 오류발생 -> 해결 (0) | 2021.01.11 |
| [#11장] 모듈과 패키지 (0) | 2021.01.09 |
| [#10장 연습문제] 처음 시작하는 파이썬 10장 연습문제 (0) | 2021.01.08 |
| [#10 파이썬 기초] 객체와 클래스2 (0) | 2021.01.08 |